After our introduction article about tools and techniques for bugfixing Vue apps, we want to take you on a journey through a real-world debugging process.
We’ll show you how we found and fixed a nasty bug in one of our projects with the help of error & performance monitoring by Sentry.
✨ Sponsored by Sentry: This post is sponsored by Sentry, but we’re describing a real-world scenario where we used their monitoring. We love to partner up with them as we enjoy their product!
The bug
Besides curating our madewith* collections for you, we also run a SaaS. Placid is a toolkit for image generation, including an API and nocode solutions.
<div class="brick__image-inner "
id="js-image-776"
v-lazy-bg="'https://madewithnetworkfra.fra1.digitaloceanspaces.com/spatie-space-production/28488/placid-4.jpg'"
style=" ">
</div>
</div>
<div class="brick__caption">
<div class="brick__caption-upper">
<a href="https://madewithvuejs.com/placid" class="brick__title">
Placid.app
</a>
<span class="brick__tagline">
Creative Automation Toolkit
</span>
</div>
<div class="brick__caption-lower">
<div class="pull-left">
<a href="/webapps">#Webapps</a>
<a href="/saas">#SaaS</a>
<a href="/laravel">#Laravel</a>
<span class="dots">...</span>
</div>
<div class="pull-right">
<div class="brick__views">
<svg class="svg-inline u__va--middle" width="20px" height="13px" viewBox="0 0 20 13" version="1.1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink">
<!-- Generator: Sketch 46.2 (44496) - http://www.bohemiancoding.com/sketch -->
<title>icon-eye-dark</title>
<desc>Created with Sketch.</desc>
<defs></defs>
<g id="Page-1" stroke="none" stroke-width="1" fill="none" fill-rule="evenodd">
<g id="Icons" transform="translate(-313.000000, -230.000000)" fill-rule="nonzero" fill="#435B71">
<g id="icon-eye-dark" transform="translate(313.000000, 230.000000)">
<path d="M9.57827924,0.0932647368 C5.40166592,0.0977121053 2.23909537,3.28527789 0.162366374,6.09013053 C-0.0164829778,6.33193046 -0.0164829778,6.66216481 0.162366374,6.90396474 C2.23923803,9.71401737 5.40085034,12.9011726 9.57827924,12.9068174 C9.57872397,12.9068178 9.57916871,12.9068178 9.57961345,12.9068174 C13.7562192,12.90237 16.9187977,9.71477 18.9955264,6.90995158 C19.1743758,6.66815165 19.1743758,6.3379173 18.9955264,6.09611737 C16.9186536,3.28603053 13.7570499,0.0989094737 9.57961345,0.0932647368 C9.57916871,0.0932643033 9.57872397,0.0932643033 9.57827924,0.0932647368 L9.57827924,0.0932647368 Z M9.57827924,1.46168579 L9.57961345,1.46168579 C12.8675916,1.46681737 15.5988249,3.96846211 17.5569468,6.50236737 C15.5985806,9.03230421 12.8660264,11.5341884 9.57961345,11.5383963 C6.29104758,11.5339489 3.55933568,9.03192789 1.60094367,6.49771474 C3.55930832,3.96777789 6.29185563,1.46589368 9.57827718,1.46168579 L9.57827924,1.46168579 Z" id="Shape"></path>
<path d="M9.57894737,3.42075158 C7.88659608,3.42075158 6.5,4.80737263 6.5,6.49969895 C6.5,8.19205947 7.88659608,9.57864632 9.57894737,9.57864632 C11.2712987,9.57864632 12.6578947,8.19205947 12.6578947,6.49969895 C12.6578947,4.80737263 11.2712987,3.42075158 9.57894737,3.42075158 Z M9.57894737,4.78917263 C10.5317492,4.78917263 11.2894737,5.54690158 11.2894737,6.49969895 C11.2894737,7.45249632 10.5317492,8.21022526 9.57894737,8.21022526 C8.62614555,8.21022526 7.86842105,7.45249632 7.86842105,6.49969895 C7.86842105,5.54690158 8.62614555,4.78917263 9.57894737,4.78917263 Z" id="Shape"></path>
</g>
</g>
</g> </div>The app is powered by web components built with Vue, and a Laravel-based queue system for generated images supported by a growing amount of servers.
Images are created by those servers screenshotting templates using a headless Chrome instance (with Puppeteer).
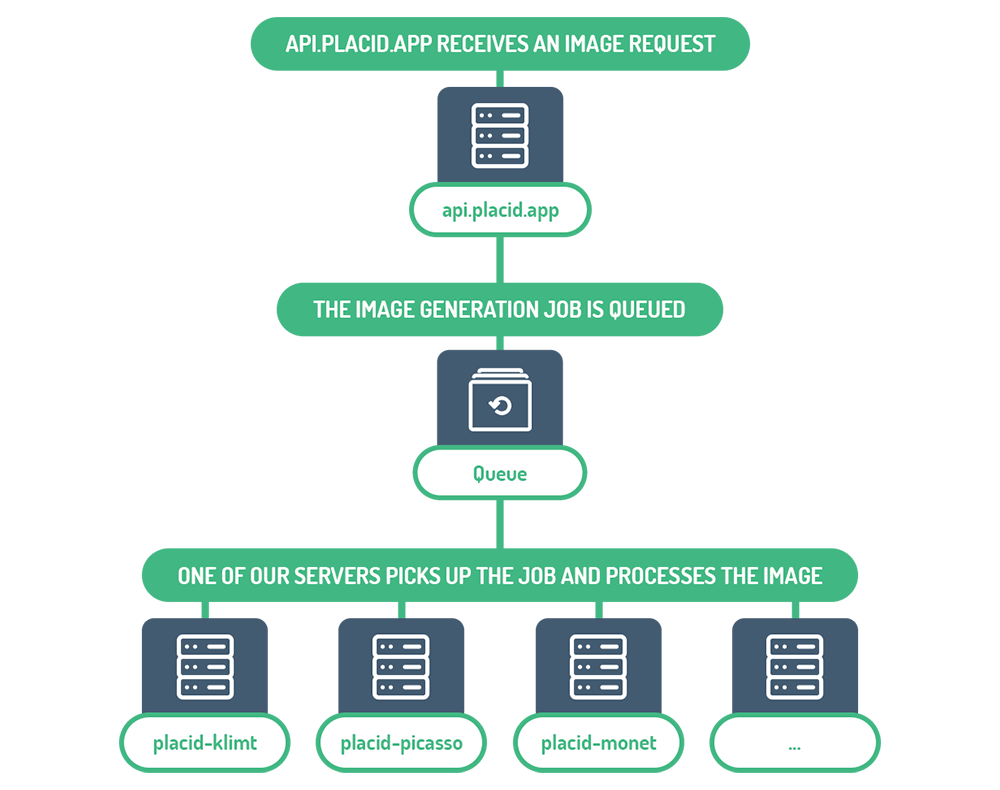
Recently we had a persisting bug where image creation would time out about 1 out of 10,000 times. It popped up in our support, where customers were wondering about sometimes having to wait a long time to get their image after clicking on a „Download“ button in the app.
The hunt
Debugging these kind of things really sucks. Besides a client-side issue it could very well be caused by a hiccup in the image generation process on any of our servers.
Those are practically unreproducible locally. You know how your browser just messes things up sometimes? Headless Chrome is no different. The timeout could be caused by a memory problem, something to do with the OS, a network delay or who knows - different moon phases maybe?
To get more infos about errors that occur in production, we had already set up monitoring with the Sentry SDKs. In their dashboard, they show you a lot of insights about the exceptions they report.
<div class="brick__image-inner "
id="js-image-50"
v-lazy-bg="'https://madewithnetworkfra.fra1.digitaloceanspaces.com/spatie-space-production/29802/sentry-vue-7.jpg'"
style=" ">
</div>
</div>
<div class="brick__caption">
<div class="brick__caption-upper">
<a href="https://madewithvuejs.com/sentry-for-vue" class="brick__title">
Sentry for Vue
</a>
<span class="brick__tagline">
Vue Error & Performance Monitoring
</span>
</div>
<div class="brick__caption-lower">
<div class="pull-left">
<a href="/dev-tools">#Dev Tools</a>
<a href="/integration">#Integration</a>
<a href="/testing">#Testing</a>
<span class="dots">...</span>
</div>
<div class="pull-right">
<div class="brick__views">
<svg class="svg-inline u__va--middle" width="20px" height="13px" viewBox="0 0 20 13" version="1.1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink">
<!-- Generator: Sketch 46.2 (44496) - http://www.bohemiancoding.com/sketch -->
<title>icon-eye-dark</title>
<desc>Created with Sketch.</desc>
<defs></defs>
<g id="Page-1" stroke="none" stroke-width="1" fill="none" fill-rule="evenodd">
<g id="Icons" transform="translate(-313.000000, -230.000000)" fill-rule="nonzero" fill="#435B71">
<g id="icon-eye-dark" transform="translate(313.000000, 230.000000)">
<path d="M9.57827924,0.0932647368 C5.40166592,0.0977121053 2.23909537,3.28527789 0.162366374,6.09013053 C-0.0164829778,6.33193046 -0.0164829778,6.66216481 0.162366374,6.90396474 C2.23923803,9.71401737 5.40085034,12.9011726 9.57827924,12.9068174 C9.57872397,12.9068178 9.57916871,12.9068178 9.57961345,12.9068174 C13.7562192,12.90237 16.9187977,9.71477 18.9955264,6.90995158 C19.1743758,6.66815165 19.1743758,6.3379173 18.9955264,6.09611737 C16.9186536,3.28603053 13.7570499,0.0989094737 9.57961345,0.0932647368 C9.57916871,0.0932643033 9.57872397,0.0932643033 9.57827924,0.0932647368 L9.57827924,0.0932647368 Z M9.57827924,1.46168579 L9.57961345,1.46168579 C12.8675916,1.46681737 15.5988249,3.96846211 17.5569468,6.50236737 C15.5985806,9.03230421 12.8660264,11.5341884 9.57961345,11.5383963 C6.29104758,11.5339489 3.55933568,9.03192789 1.60094367,6.49771474 C3.55930832,3.96777789 6.29185563,1.46589368 9.57827718,1.46168579 L9.57827924,1.46168579 Z" id="Shape"></path>
<path d="M9.57894737,3.42075158 C7.88659608,3.42075158 6.5,4.80737263 6.5,6.49969895 C6.5,8.19205947 7.88659608,9.57864632 9.57894737,9.57864632 C11.2712987,9.57864632 12.6578947,8.19205947 12.6578947,6.49969895 C12.6578947,4.80737263 11.2712987,3.42075158 9.57894737,3.42075158 Z M9.57894737,4.78917263 C10.5317492,4.78917263 11.2894737,5.54690158 11.2894737,6.49969895 C11.2894737,7.45249632 10.5317492,8.21022526 9.57894737,8.21022526 C8.62614555,8.21022526 7.86842105,7.45249632 7.86842105,6.49969895 C7.86842105,5.54690158 8.62614555,4.78917263 9.57894737,4.78917263 Z" id="Shape"></path>
</g>
</g>
</g> </div>But to pinpoint this bug we needed more context to know what process caused the timeout. So we added distributed tracing, allowing us to connect all the involved events from our frontend (Vue) and backend (Laravel) services. In short: We could follow the bug through all layers of our app 🕵️
The evidence
As soon as a new error of this type got reported in our Sentry dashboard, we started investigating. By viewing the full trace of the error we could see what processes happened before:
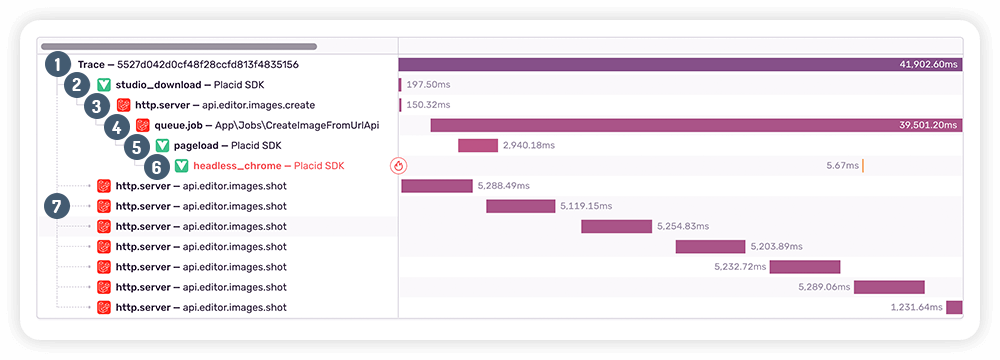
- The user opens the page and the trace is created
- The user clicked the „Download“ button in our Placid Studio component
- The API controller receives the request and creates a queue job
- The queue job gets picked up by our server
placid-klimt(yes, they’re all named after painters) and starts processing by starting a headless Chrome instance - The headless Chrome booted up (it has the Sentry SDK embedded as well!)
- 💥 The Sentry Vue SDK captures the error
- Meanwhile, the User UI continues to try to fetch the image
The lead
Looking into those processes, what clues did we find that could help us find the root cause of the timeout?

- We could see that this error happens inside of the headless Chrome instance
- The version of the Chrome instance was outdated and several versions back of what it should have been consistently on all servers
- The
placid-klimtserver seemed to be guilty
The solution
We started examining placid-klimt and found it was using an outdated Chrome version because of a failing bash script that should have updated it. Issues with headless Chrome are not unusual in our workflow, so this was very likely causing a regression.
Every time placid-klimt took a job out of the queue, this bug had a chance of occurring. No wonder we could not reproduce that locally, but it made sense now! Fixing it was a piece of cake compared to finding it.
Fixing bugs across your stack
Full-stack monitoring helped us to connect the bug that surfaced on a button click to its root cause, hidden in our backend stack. Not unusual if your architecture gets a bit more complex!
In our bootstrapped SaaS with a tiny team I had to fix the bug myself anyway 🙃, but this would definitely help larger teams to quickly assign issues to the right person.
While you can use the open-source SDKs by Sentry for Vue, Laravel and many more for free, this specific monitoring setup requires a Sentry subscription – and some curiosity about setting up distributed tracing 🤓
I’m as excited about bugfixing as the next developer (so, not particularly), but investing into your monitoring process saves you the time and nerves you’d else spend digging around in the dark.

